-
[NetworkX] Assignment 1 - Creating and Manipulating GraphsData & ML & AI/NetworkX 2022. 10. 30. 03:47반응형
본 게시물은 Coursera의 Applied Social Network Analysis in Python(by Daniel Romero)를 통해 자습하며 작성한 게시물입니다.
이 Assignment는 Coursera Jupyter 콘솔에서만 제대로 진행할 수 있습니다.
(데이터 파일을 따로 제공하지 않기 때문입니다.)
개괄 원본
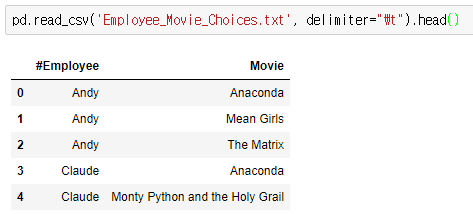
Eight employees at a small company were asked to choose 3 movies that they would most enjoy watching for the upcoming company movie night. These choices are stored in the file `Employee_Movie_Choices.txt`.
A second file, `Employee_Relationships.txt`, has data on the relationships between different coworkers.
The relationship score has value of `-100` (Enemies) to `+100` (Best Friends). A value of zero means the two employees haven't interacted or are indifferent. Both files are tab delimited.개괄 해석 (많은 의역, 생략 및 요약)
- Employee_Movie_Choices.txt
- 사람 8명, 한사람당 3개 영화 선택
- 구분자: tab
- Employee_Relationships.txt
- 동료간의 관계 데이터
- 관계점수: -100(웬수) ~ +100(극호), 0(만난적 없음 or 무관심)
- 구분자: tab

이 데이터에는 header가 없습니다. 기본 제공코드 (더보기 안에 있어요)
더보기import networkx as nx import pandas as pd import numpy as np from networkx.algorithms import bipartite # This is the set of employees employees = set(['Pablo', 'Lee', 'Georgia', 'Vincent', 'Andy', 'Frida', 'Joan', 'Claude']) # This is the set of movies movies = set(['The Shawshank Redemption', 'Forrest Gump', 'The Matrix', 'Anaconda', 'The Social Network', 'The Godfather', 'Monty Python and the Holy Grail', 'Snakes on a Plane', 'Kung Fu Panda', 'The Dark Knight', 'Mean Girls']) # you can use the following function to plot graphs # make sure to comment it out before submitting to the autograder def plot_graph(G, weight_name=None): ''' G: a networkx G weight_name: name of the attribute for plotting edge weights (if G is weighted) ''' %matplotlib notebook import matplotlib.pyplot as plt plt.figure() pos = nx.spring_layout(G) edges = G.edges() weights = None if weight_name: weights = [int(G[u][v][weight_name]) for u,v in edges] labels = nx.get_edge_attributes(G,weight_name) nx.draw_networkx_edge_labels(G,pos,edge_labels=labels) nx.draw_networkx(G, pos, edges=edges, width=weights); else: nx.draw_networkx(G, pos, edges=edges);
Question 1
Using NetworkX, load in the bipartite graph from Employee_Movie_Choices.txt and return that graph.
This function should return a networkx graph with 19 nodes and 24 edges- Employee_Movie_Choices.txt 에서 데이터 읽어와서 Bipartite Graph를 만드는 함수를 만들어라
- 19개 노드, 24개 엣지가 나와야된다
- 힌트: nx.read_edgelist()
해결방법(더보기 안에 있어요)
더보기Question 1 해결방법
def answer_one(): G = nx.read_edgelist('Employee_Movie_Choices.txt', delimiter="\t") return G결과 확인
plot_graph(answer_one(), weight_name=None)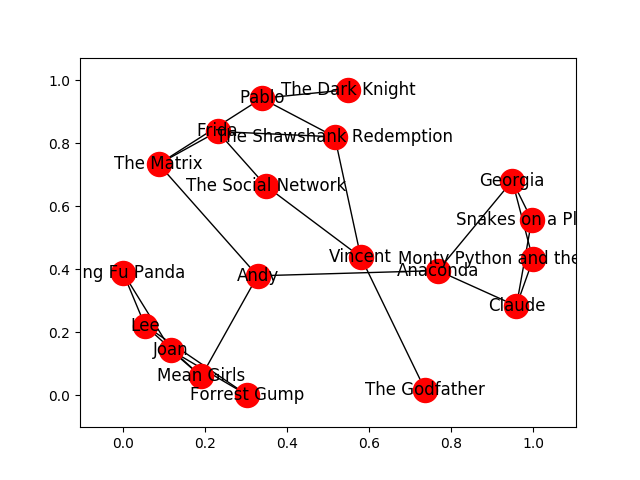
Question 2
Using the graph from the previous question, add nodes attributes named 'type' where movies have the value 'movie' and employees have the value 'employee' and return that graph.
This function should return a networkx graph with node attributes {'type': 'movie'} or {'type': 'employee'}- Question1에서 만든 그래프에 노드 속성을 추가해라
- 영화에는 {'type':'movie'}, 사람에는 {'type': 'employee'}
- 힌트: G.add_nodes_from()
해결방법(더보기 안에 있어요)
더보기Question 2 해결방법
def answer_two(): G = answer_one() G.add_nodes_from(employees, type='employee') G.add_nodes_from(movies, type='movie') return G결과 확인
G = answer_two() G.nodes(data=True) # 결과 [('Andy', {'type': 'employee'}), ('Anaconda', {'type': 'movie'}), ('Mean Girls', {'type': 'movie'}), ('The Matrix', {'type': 'movie'}), ... 생략
Question 3
Find a weighted projection of the graph from answer_two which tells us how many movies different pairs of employees have in common.
This function should return a weighted projected graph.- employees기준으로 가중투영그래프 만들어라
- (가중치: 사람A와 사람B가 각각 보겠다고 말한 영화 중, 몇 개가 일치하는가 = 공통영화 수)
- 힌트: bipartite.weighted_projected_graph()
[NetworkX] Projected Graph 투영그래프 (Bipartite Graph 활용)
Projected Graph 투영 그래프 X, Y 집단(set)로 이루어진 Bipartite Graph에서, X나 Y 둘 중 하나의 집단을 기준으로 투영한 그래프를 Projected Graph라고 합니다. 여기서 투영(projection)이란, 두개의 집단으..
brain-nim.tistory.com
해결방법(더보기 안에 있어요)
더보기Question 3 해결방법
def answer_three(): B = answer_two() weighted_projection = bipartite.weighted_projected_graph(B, employees) return weighted_projection결과 확인
plot_graph(answer_three(), weight_name='weight')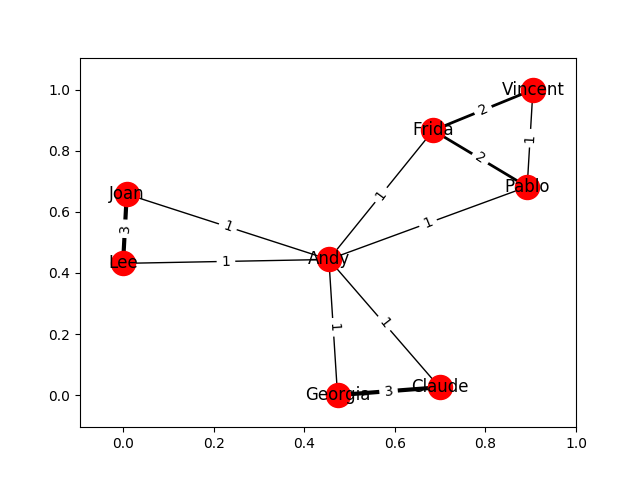
Question 4
Suppose you'd like to find out if people that have a high relationship score also like the same types of movies.
Find the Pearson correlation ( using DataFrame.corr() ) between employee relationship scores and the number of movies they have in common. If two employees have no movies in common it should be treated as a 0, not a missing value, and should be included in the correlation calculation.
This function should return a float.- 관계점수가 높을수록 같은 유형의 영화를 좋아하는지 확인해라
- "동료간 관계점수"와 "공통 영화 수" 사이의 Pearson 상관관계를 확인해라(DataFrame.corr() 사용)
- 공통영화가 없는 경우에도 0으로 처리해서 상관계산해라
해결방법(더보기 안에 있어요)
더보기Question 4 해결방법
def answer_four(): G = answer_three() df = pd.read_csv('Employee_Relationships.txt', delimiter='\t', header=None) # 공통영화 수 칼럼 생성(default = 0) df[3]=0 df.columns = ['E1','E2','relationship','same_movie'] # 엣지의 weight 속성값을 이용해 df['same_movie'] 값 변경하기 for E1, E2, w in G.edges(data = True): df.loc[((df['E1']==E1)&(df['E2']==E2))|((df['E1']==E2)&(df['E2']==E1)),'same_movie'] = w['weight'] return df.corr().loc['relationship','same_movie']결과 확인
answer_four() # 0.78839622217334759

위와 동일한 코드로도 처음엔 20점이 나왔습니다.
"????"하면서 이해가 안되다가 '설마...'하며 중간중간 결과 확인하려고 만들었던 셀들을 지웠더니
그제야 100점이 나왔습니다.
Coursera에서는 정말 문제가 요구하는 셀들만 남겨놔야 채점이 제대로 되나봅니다.
반응형'Data & ML & AI > NetworkX' 카테고리의 다른 글
[NetworkX] 너비 우선 탐색, 트리 구조 그리기 (0) 2022.11.02 [NetworkX] 경로의 개념, 가장 짧은 경로 찾기 (0) 2022.11.01 [NetworkX] Projected Graph 투영그래프 (Bipartite Graph 활용) (0) 2022.10.28 [NetworkX] Bipartite Graph(양분 그래프) 그리기 (0) 2022.10.27 [NetworkX] 양분그래프, Bipartite Graph (파이썬 네트워크 분석 9) (0) 2022.10.22 - Employee_Movie_Choices.txt