Data & ML & AI/LLM
[LlamaIndex] Llama-Index와 DB 연동하기(DatabaseReader, feat. agent)
뇌님
2024. 10. 8. 21:31
반응형
LlamaIndex를 이용하면 DB와 LLM을 쉽게 연결할 수 있습니다.
주관적으로는 LangChain보다 더 간편하다고 생각합니다.
0. 세팅
1) pip install
pip install llama-index # 라마인덱스 기본
pip install llama-index-readers-database # DB와 연결
2) LLM 세팅
a. Open AI의 ChatGPT를 사용하는 경우
# Open AI의 ChatGPT를 사용하는 경우
import os
from llama_index.core import Settings
os.environ["OPENAI_API_KEY"] = "$$$$$$$$$$$$$$"
llm = OpenAI(model="gpt-3.5-turbo-0613")
Settings.llm = llm
b. AWS Bedrock을 사용하는 경우 (모델ID 확인방법 참고)
# AWS Bedrock을 사용하는 경우
from llama_index.core import Settings
from llama_index.llms.bedrock import Bedrock
access_key = "$$$$$$$$$$$$$$$$$"
secret_key = "$$$$$$$$$$$$$$$$$"
region = "us-east-1"
llm = Bedrock(
model = "anthropic.claude-v2", # 모델ID 확인 후 변경
aws_access_key_id = access_key,
aws_secret_access_key = secret_key,
region_name = region,
)
Settings.llm = llm
c. Ollama를 사용하는 경우 (Ollama 설치방법 참고)
# Ollama를 사용하는 경우
from llama_index.core import Settings
from llama_index.llms.ollama import Ollama
llm = Ollama(model="llama3.1:70b", request_timeout=180.0)
Settings.llm = llm
1. DB연결
from llama_index.readers.database import DatabaseReader
db = DatabaseReader(
scheme="postgresql", # Database Scheme. 이 예시에서는 PostgreSQL
host="host", # "localhost" 혹은 host 주소
port="5432", # Database Port. 이 예시에서는 Postgre이므로 5432
user="userName", # Database User
password="yourPassword", # Database Password
dbname="dbname", # Database Name
)
# 정상연결 테스트
query = "SELECT * FROM contents"
texts = db.sql_database.run_sql(command=query)
print(type(texts)) # <class 'tuple'>
print(texts) # ('[(1, 2, \'해조류가 뭔가요?\', \'<p>해조류란 ~~~이때 texts에서는 칼럼명 정보가 사라집니다.
2. Index 생성
# document 생성
query = "SELECT * FROM contents"
documents = db.load_data(query=query)
# 테스트
print(type(documents)) # <class 'list'>
print(documents) # [Document(id_='84dadd97-06d9-4ee3-9356-7aed4166fdeb', ~~
# index 생성
index = VectorStoreIndex.from_documents(documents)이때 documents에는 칼럼정보가 그대로 살아있습니다.
3. 활용
1) index → 쿼리엔진
query_engine = index.as_query_engine(similarity_top_k=3)
response = query_engine.query('해조류 안에는 어떤 성분들이 들어있나요?')
print(response)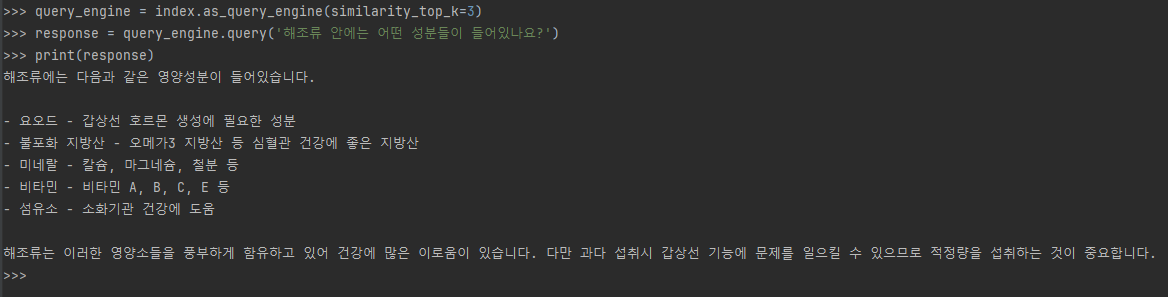
2) index → 쿼리엔진 → tool → agent
from llama_index.core.tools import QueryEngineTool
from llama_index.core.agent import ReActAgent
# tool 생성
health_knowledge_tool = QueryEngineTool.from_defaults(
query_engine,
name="Health_Knowledge_tool",
description="A useful tool for answering questions about health knowledge."
)
# agent 생성
agent = ReActAgent.from_tools([health_knowledge_tool], llm=llm, verbose=True)
# 테스트
response = agent.chat('해조류 안에는 어떤 성분들이 들어있나요?')
print(response)
참고: https://docs.llamaindex.ai/en/stable/examples/data_connectors/DatabaseReaderDemo/
Database Reader - LlamaIndex
docs.llamaindex.ai
반응형