-
모델 파일 load 속도 비교 (joblib vs Pickle vs cPickle)Data & ML & AI/기타 모델, 알고리즘, 툴 2023. 6. 28. 18:46반응형
프로젝트를 진행하는 과정에서
모델을 돌리는 시간보다 모델파일을 불러오는 시간이 훨씬 길다는 문제가 발생했습니다.
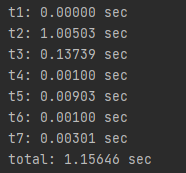
t2가 모델 로딩하는데 걸리는 시간 지금까지 저는 특별한 이유 없이 관습적으로 joblib을 사용하고 있었는데,
이번 기회에 joblib과 Pickle, 그리고 cPickle의 로딩 속도를 비교하고 선택해보기로 했습니다.
1. 레퍼런스
우선 아래의 stackoverflow 글을 확인했습니다.
What are the different use cases of joblib versus pickle?
Background: I'm just getting started with scikit-learn, and read at the bottom of the page about joblib, versus pickle. it may be more interesting to use joblib’s replacement of pickle (joblib....
stackoverflow.com
#comapare pickle loaders from time import time import pickle import os import _pickle as cPickle from sklearn.externals import joblib file = os.path.join(os.path.dirname(os.path.realpath(__file__)), 'database.clf') t1 = time() lis = [] d = pickle.load(open(file,"rb")) print("time for loading file size with pickle", os.path.getsize(file),"KB =>", time()-t1) t1 = time() cPickle.load(open(file,"rb")) print("time for loading file size with cpickle", os.path.getsize(file),"KB =>", time()-t1) t1 = time() joblib.load(file) print("time for loading file size joblib", os.path.getsize(file),"KB =>", time()-t1) time for loading file size with pickle 79708 KB => 0.16768312454223633 time for loading file size with cpickle 79708 KB => 0.0002372264862060547 time for loading file size joblib 79708 KB => 0.000684976577758789179708KB의 DB파일을 이용해서 load 속도를 테스트 해본 결과,
- 속도: cPickle > joblib >>>>>> pickle
- pickle이 0.1677초로 가장 느림
- cpickle이 0.0002초로 가장 빠름 (pickle에 비해 무려 약 700배가 빨라요!)
- joblib이 0.0007초로 cpickle보다는 약 3배 느리지만 pickle보다는 약 250배 빠름
위의 테스트 결과와 같다면 제 프로젝트에서의 경우,
joblib에서 cPickle로 변경하면 약 3배만 빨라지고, pickle로 변경하면 오히려 느려지므로 살짝 암담했습니다.
그래도 실험을 진행해봤습니다.
2. 본 프로젝트의 경우
import os from time import time import joblib import pickle import _pickle as cPickle # model files j_file = './model/model20230628174704480319' p_file = './model/model20230628174704480319.p' cp_file = './model/model20230628174704480319.cp' # joblib t = time() d = joblib.load(j_file) print("time for loading file size with joblib", os.path.getsize(j_file), "KB =>", time()-t, 'sec') # pickle t = time() d = pickle.load(open(p_file,"rb")) print("time for loading file size with pickle", os.path.getsize(p_file), "KB =>", time()-t, 'sec') # cPickle t = time() d = cPickle.load(open(cp_file,"rb")) print("time for loading file size with cpickle", os.path.getsize(cp_file), "KB =>", time()-t, 'sec') time for loading file size with joblib 49455808 KB => 1.1096792221069336 sec time for loading file size with pickle 49455234 KB => 0.08711957931518555 sec time for loading file size with cpickle 49455234 KB => 0.09377574920654297 sec동일한 모델 변수를 joblib, pickle, cpickle를 이용해서 dump한 후
그 결과 생성된 49455234~49455808KB의 모델파일을 이용해서 load 속도를 테스트해본 결과,

와 많이 빨라졌습니다! - 속도: pickle > cPickle >>> joblib
- joblib이 1.1097초로 가장 느림
- pickle이 0.0871초로 가장 빠름 (joblib에 비해 약 13배 더 빠릅니다!)
- cPickle이 0.0938초로 joblib보다는 약 12배 빠르나, pickle에 비해 살짝 느림
위 stackoverflow에서의 실험결과와는 정반대의 결과가 나왔습니다!
가장 느렸던 pickle이 가장 빠르게 나왔고, 비교적 매우 빨랐던 joblib이 가장 느렸습니다.
무엇보다 신기했던건, pickle의 속도가 cPickle보다 빨랐다는 점입니다.
cPickle의 경우 C로 구현되어있어 상대적으로 더 빠르다고 알고있었기 때문입니다.
몇번 더 테스트해보니, pickle과 cPickle의 속도가 일치하는 경우는 있어도, cPickle이 더 빠른 경우는 나타나지 않았습니다.
번외) 왜 pickle의 속도가 cPickle보다 빠른 경우가 발생하는가?
진지하게 검색해본건 아니고, 그냥 chatGPT에게 물어본 결과를 공유합니다.
Q: Why sometimes pickle's load speed is faster than cpickle?
A:
The speed of loading pickle and cpickle files can vary depending on the specific circumstances and configurations. However, there are a few reasons why pickle load speed might be faster than cpickle in certain cases:
1. Protocol Version: Pickle and cpickle use different protocol versions for serialization. The protocol version determines the format and efficiency of the serialized data. cpickle generally uses a more compact binary format (protocol 2), while pickle uses a text-based format (protocol 0 or 1). In some cases, the text-based format used by pickle can be faster to load compared to the binary format used by cpickle.
2. Data Size: The size of the data being serialized and deserialized can also impact the loading speed. cpickle's binary format is generally more efficient for large data structures since it produces smaller file sizes. However, when dealing with relatively small data, the overhead of parsing binary data in cpickle might slow down the loading process compared to pickle's text-based format.
3. System and Library Configuration: The performance of pickle and cpickle can also be influenced by the underlying system and library configurations. Different implementations and versions of the Python interpreter or related libraries may introduce optimizations or differences that affect the loading speed.
It's worth noting that cpickle is generally recommended for performance-critical scenarios due to its faster serialization and deserialization speed compared to pickle. However, in some cases, the specific characteristics of the data and the system can lead to pickle loading faster than cpickle. To determine the most efficient option for your specific use case, it's recommended to benchmark the loading times using representative data and compare the results.pickle과 cpickle의 로딩 속도가 경우에 따라서 pickle이 더 빠를 수 있는 이유는 다음과 같습니다:
1. 프로토콜 버전: pickle과 cpickle은 직렬화를 위해 서로 다른 프로토콜 버전을 사용합니다. 프로토콜 버전은 직렬화된 데이터의 형식과 효율성을 결정합니다. 일반적으로 cpickle은 더 간결한 이진 형식(프로토콜 2)을 사용하고, pickle은 텍스트 기반 형식(프로토콜 0 또는 1)을 사용합니다. 텍스트 기반 형식인 pickle이 이진 형식인 cpickle에 비해 로딩 속도가 더 빠를 수 있습니다.
2. 데이터 크기: 직렬화 및 역직렬화되는 데이터의 크기도 로딩 속도에 영향을 줄 수 있습니다. cpickle의 이진 형식은 일반적으로 대량의 데이터 구조에 대해 더 효율적이며 작은 파일 크기를 생성합니다. 그러나 상대적으로 작은 데이터를 처리할 때는 cpickle에서 이진 데이터를 구문 분석하는 오버헤드로 인해 pickle의 텍스트 기반 형식이 로딩 속도를 더 빠르게 만들 수 있습니다.
3. 시스템 및 라이브러리 설정: pickle과 cpickle의 성능은 기반이 되는 시스템 및 라이브러리 설정에도 영향을 받을 수 있습니다. 파이썬 인터프리터 또는 관련 라이브러리의 다른 구현 및 버전은 로딩 속도에 영향을 미치는 최적화 또는 차이점을 도입할 수 있습니다.
일반적으로 성능이 중요한 상황에서는 더 빠른 직렬화 및 역직렬화 속도로 인해 cpickle을 권장합니다. 그러나 일부 경우에는 데이터의 특성과 시스템의 특정 요소로 인해 pickle이 cpickle보다 더 빠를 수 있습니다. 특정 사용 사례에 가장 효율적인 옵션을 결정하려면 대표적인 데이터를 사용하여 로딩 시간을 벤치마크하고 결과를 비교하는 것이 좋습니다.파일 load 속도에 문제가 있다면 직접 실험을 해보고 선택합시다.
반응형'Data & ML & AI > 기타 모델, 알고리즘, 툴' 카테고리의 다른 글
LLM 챗봇 개발하기 더 유용한 프레임워크는? (Gradio vs Streamlit) (4) 2025.03.10 [UI/UX] AI 디자인툴 5개 비교 (Figma vs Creatie vs Motiff vs Uizard vs Galileo) (0) 2025.01.01