-
1. 판다스를 활용한 자료탐색 기초(+그래프그리기)Data & ML & AI/Pandas & Scikit-Learn 2022. 5. 15. 22:21반응형
회사 자료를 직접 활용해서 글을 작성하는건 아쉽게도(?) 불가능하니 모두가 관심이 많은 주식 관련 데이터를 만져볼까 합니다.
kiwoom API로 데이터를 수집할까 했다가 반년쯤 전에 네이버 주식페이지 크롤러를 만들어놨던게 생각나서 그걸 다시 돌려봤습니다.
짧게 종목코드(000000)~(005000)사이의 250개 종목만 들어있는 csv 파일입니다.# matplotlib import matplotlib as mpl import matplotlib.pyplot as plt import matplotlib.font_manager as fm plt.rcParams['axes.unicode_minus'] = False # matplotlib 마이너스기호 표시 plt.rc('font', family='NanumGothic') # matplotlib 한글폰트 표시 %matplotlib inline # 주피터노트북 내에 matplotlib 출력 # pandas import pandas as pd # data df = pd.read_csv('stock_market.csv')1. 데이터 개괄 살펴보기
데이터프레임을 활용해 데이터 개괄을 살펴보는 방식은 여러가지가 있습니다.
여기서는 기본적인 3가지 방식만 먼저 보겠습니다.- info()
- describe()
- head(), tail()
1) info()
df.info()<class 'pandas.core.frame.DataFrame'> RangeIndex: 250 entries, 0 to 249 Data columns (total 29 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 ID 250 non-null object 1 Name 250 non-null object 2 Market 250 non-null object 3 Category 250 non-null object 4 Capital 250 non-null int64 5 PER 249 non-null float64 6 EPS 250 non-null int64 7 ROE 249 non-null float64 8 PBR 250 non-null float64 9 EV 157 non-null float64 10 BPS 250 non-null int64 11 Group_PER 250 non-null float64 12 Revenue 250 non-null int64 13 Operating_Income 250 non-null int64 14 Net_Income 250 non-null int64 15 Dividend 189 non-null float64 16 Debt 250 non-null float64 17 Debt_continuous 250 non-null int64 18 Retention 250 non-null float64 19 Retention_Continuous 250 non-null int64 20 Open 250 non-null int64 21 High 250 non-null int64 22 Low 250 non-null int64 23 Close 250 non-null int64 24 DaytoDay 250 non-null int64 25 Volume 250 non-null int64 26 Highest_Price 250 non-null int64 27 Highest_Date 250 non-null object 28 update_date 250 non-null object dtypes: float64(8), int64(15), object(6) memory usage: 56.8+ KB.info()를 활용하면 데이터 개수와 각 칼럼의 데이터타입, null 여부를 확인할 수 있어 유용합니다.
2) .describe()
df.describe()
3) .head(), .tail()
df.head(3)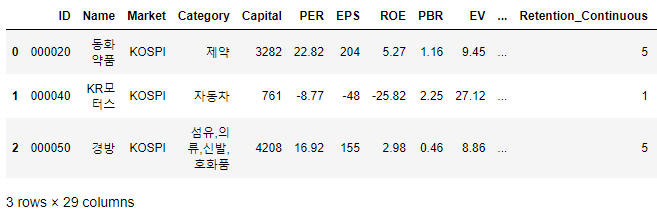
.head()나 .tail()을 활용하면 실제 데이터를 볼 수 있기 때문에 직관적인 파악이 가능하다는 장점이 있습니다.
2. 범주형 자료 탐색
위의 방식들만으로는 Market와 같은 범주형자료의 분포를 파악하기에 한계가 있습니다.
판다스 메소드 value_counts() 를 활용하면 간단히 범주형자료들을 확인해 볼 수 있습니다.- value_counts()
1) value_counts()
df.Market.value_counts()KOSPI 237 KOSDAQ 13 Name: Market, dtype: int64df['Category'].value_counts()제약 24 식품 22 증권 20 화학 15 건축자재 15 섬유,의류,신발,호화품 14 건설 14 철강 13 복합기업 13 자동차부품 13 손해보험 10 항공화물운송과물류 7 음료 6 종이와목재 6 비철금속 5 포장재 5 화장품 3 기계 3 항공사 3 생명보험 3 자동차 3 반도체와반도체장비 3 가정용기기와용품 3 석유와가스 2 디스플레이장비및부품 2 전자장비와기기 2 무역회사와판매업체 2 전기장비 2 전기제품 2 가스유틸리티 2 백화점과일반상점 1 도로와철도운송 1 식품과기본식료품소매 1 전문소매 1 핸드셋 1 생물공학 1 에너지장비및서비스 1 레저용장비와제품 1 컴퓨터와주변기기 1 무선통신서비스 1 방송과엔터테인먼트 1 건강관리장비와용품 1 가구 1 Name: Category, dtype: int64종목코드 00000~005000 사이의 250개 종목들은 KOSPI가 압도적으로 많고, 제약회사와 식품회사가 상대적으로 많음을 알 수 있습니다.
좀 더 직관적으로 확인하고 싶으니 시각화를 해봅시다.
2) 시각화
df['Market'].value_counts().plot(kind="pie")
df.Category.value_counts()[:20].plot(kind="bar")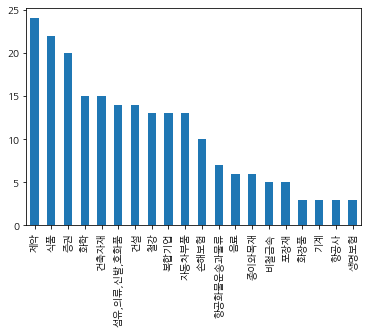
bar그래프에서는 상위 20개 카테고리만 살펴보았습니다.
도표로 보니 좀 더 직관적입니다.3. 연속형 자료 탐색
대략적인 연속형 자료 탐색은 1. 데이터 개괄 살펴보기에서 .describe()를 통해 간단하게 살펴보았습니다만,
숫자로만 보니 그닥 와닿지가 않습니다. 연속형 자료의 분포를 좀 더 살펴봅시다.- skew() : 왜도(skewness)
- kurtosis() : 첨도(kurtosis)
1) skew()
df.skew()Capital 12.004460 PER -1.424783 EPS -3.388658 ROE 6.757212 PBR 2.424926 EV 10.573150 BPS 6.032474 Group_PER 1.814353 Revenue 4.411730 Operating_Income 11.237130 Net_Income 12.101541 Dividend 1.220583 Debt 0.707430 Debt_continuous 1.325841 Retention 6.810874 Retention_Continuous -0.033400 Open 4.414171 High 4.470675 Low 4.438313 Close 4.500973 DaytoDay 6.923529 Volume 11.993030 Highest_Price 4.347724 dtype: float64Debt와 Retention_Continuous는 비교적 0과 가깝지만,
특히 Capital과 Net_Income등은 왜도 값이 12로, 값들이 왼쪽으로 치우쳐져있음을 알 수 있습니다.그럼 실제 모습은 어떨지 그래프로도 확인해보겠습니다.
df[['Debt', 'Retention_Continuous', 'Capital', 'Net_Income']].hist(bins=50, figsize=(10,10))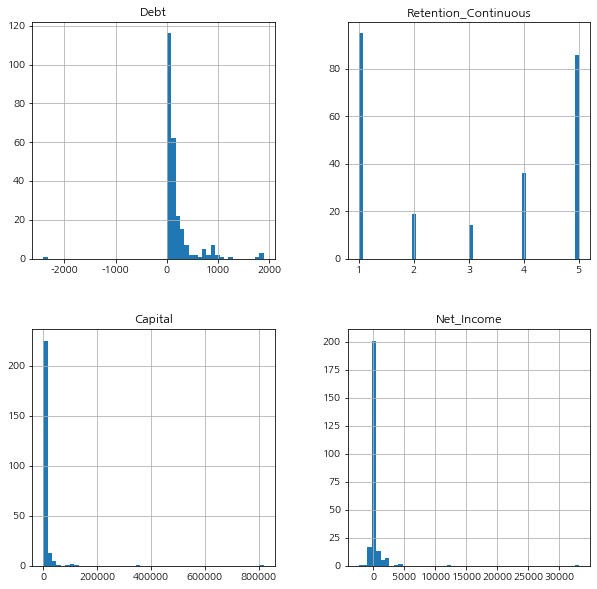
Debt와 Retention_Continuous는 0과 가까워 비교적 정규분포와 비슷한 모양을 띠지 않을까 기대했지만,
Debt에서는 빚이 마이너스 수치를 나타내는 이해하기 힘든 데이터가 존재하므로 한번 검토해봐야 함을 알 수 있습니다.
Retention_Continuous에서는 정규분포와는 상하반전된 형태로 좌우 균형을 나타내기 때문에 0과 유사한 값이 나타났음을 알 수 있습니다.2) kurtosis()
df.kurtosis()Capital 160.106356 PER 23.315257 EPS 30.061399 ROE 96.289091 PBR 16.090916 EV 123.121259 BPS 49.387270 Group_PER 3.789701 Revenue 21.202937 Operating_Income 149.662412 Net_Income 165.134548 Dividend 1.087868 Debt 19.171876 Debt_continuous 0.497723 Retention 55.890376 Retention_Continuous -1.796421 Open 25.257447 High 26.151345 Low 25.614375 Close 26.553923 DaytoDay 64.312979 Volume 165.830439 Highest_Price 23.484320 dtype: float64Debt_continuous는 비교적 0과 가까워 첨도가 정규분포와 유사한 모습이지만,
특히 Capital과 Net_Income등은 첨도 값이 160이나 되어서, 값들이 좁은 영역에 매우 몰려있음을 알 수 있습니다.df[['Debt_continuous', 'Capital']].hist(bins=50, figsize=(10,5))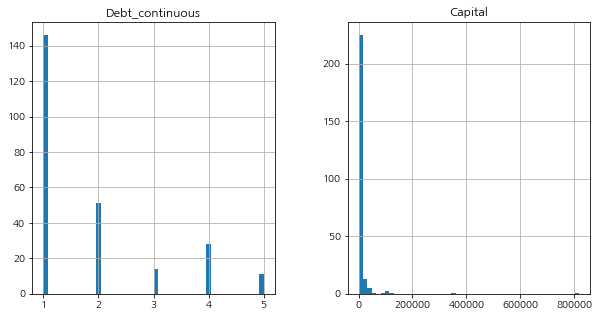
매우 뾰족한 Capital에 비해, Debt_continuous는 비교적 완만한 첨도를 나타내는 것을 확인할 수 있습니다.
반응형'Data & ML & AI > Pandas & Scikit-Learn' 카테고리의 다른 글
5. 판다스를 활용한 로그변환 (3) 2022.05.30 4. 판다스를 활용한 이상치 처리(boxplot, IQR) (0) 2022.05.29 3. 판다스를 활용한 Null값 대체(특정값, 평균, 특정함수) (0) 2022.05.24 2. 판다스를 활용한 Null값 제거 (결측행, 결측열 제거) (0) 2022.05.23 0. 들어가는 말 (1) 2022.05.14