-
3. 판다스를 활용한 Null값 대체(특정값, 평균, 특정함수)Data & ML & AI/Pandas & Scikit-Learn 2022. 5. 24. 19:32반응형
지난 포스트에서는 데이터에 존재하는 결측값(Null값)을 일방적으로 제거했습니다.
2. 판다스를 활용한 Null값 제거 (결측행, 결측열 제거)
지난번 다루었던 주식데이터, stock_market.csv의 몇 칼럼에서 결측값(null값, NaN)이 발견되었습니다. 오늘은 결측값(missing value)들을 몇가지 방법으로 처리해 보겠습니다. 결측값를 처리하는 방법은
brain-nim.tistory.com
이번에는 그 대신, 비어있는 자리에 다른 값을 넣어 활용 가능한 형태로 만들어 보겠습니다.
stock_market.csv는 칼럼 개수가 많아 한눈에 보기 힘드므로, 지난 포스트에서처럼 몇개의 칼럼만 선택해 사용해보겠습니다.
# pandas import pandas as pd # data df = pd.read_csv('stock_market.csv') sample_df = df[['ID', 'Category', 'Name', 'PER', 'EPS', 'ROE', 'Dividend', 'Close']] sample_df.head(5)
1. 결측값 대체
결측 자리에 또다른 임의의 값을 넣는 방법은 크게 4가지로 구분할 수 있습니다.
- 특정값으로 대체한다.
- 평균(+ 최대, 최소, 중앙값 등)으로 대체한다.
- 집단 평균값으로 대체한다.
- 기타 함수를 정의해 사용한다.
1) 특정값으로 대체한다: fillna()
fillna()를 이용하면 결측자리에 원하는 값이나 문자를 채워넣을 수 있습니다.
stock_markt.csv에서,
배당(Dividend)이 결측인 부분은 0으로 채워넣어도 될 것 같습니다.
적어도 지난 분기엔 배당이 없었다는 뜻이니까요.
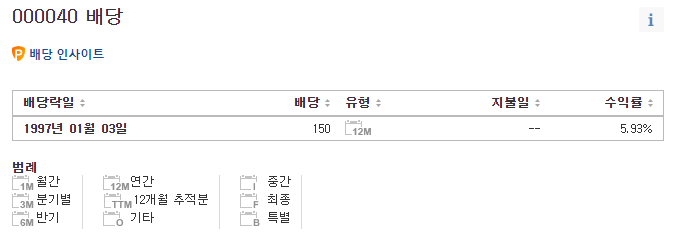
https://kr.investing.com/equities/s-t-motors-dividends 여기는 97년에 단 한 번 배당을 준걸로 보이네요.
(실제로 20년 이상 안줬던건지는 모르겠습니다만 적어도 지난분기에 안줬던건 확실하네요!).fillna(0)으로 Dividend의 null값들을 0으로 대체하였습니다.
fill_Dividend_df = sample_df.copy() fill_Dividend_df['Dividend'] = sample_df['Dividend'].fillna(0) fill_Dividend_df
Dividend가 비어있던 약 60개의 값이 모두 0으로 채워졌습니다! 2) 평균으로 대체한다 : fillna(df.mean())
250개 종목 중 유일하게 PER과 ROE가 비어있는 삼일씨엔에스(004440)의 결측치를 처리해보겠습니다.
fill_Dividend_df.iloc[222:225]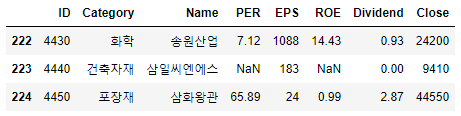
1)에서처럼 특정한 값을 직접 지정하지 않더라도 결측치 대체가 가능합니다.
.fillna()안에 df.mean()을 넣으면 데이터프레임의 평균값을 결측치의 대체값으로 사용할 수 있습니다.fill_Dividend_df.mean() # PER 4.545221 # EPS 209.928000 # ROE 6.775100 # Dividend 1.951720 # Close 39294.172000 # dtype: float64 fill_df = fill_Dividend_df.fillna(fill_Dividend_df.mean()) fill_df.iloc[222:225]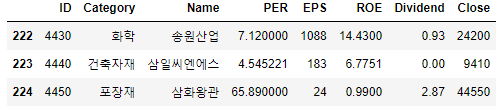
.mean() 말고도 median() , max() 등을 사용할 수 있습니다. 3) 집단별 평균값으로 대체한다: groupby()를 응용
하지만 단순히 전 종목에 대해 평균값을 구하면 너무 대충인 느낌이 듭니다.
업계별로 평균 PER은 매우 상이하기 때문이죠. (네이버 지식백과)그러니 다시 Dividend만 채운 데이터프레임 fill_Dividend_df로 돌아가서 업종별 편균값을 보겠습니다.
fill_Dividend_df.groupby('Category').mean()
삼일씨엔에스가 속한 "건축자재"의 평균 PER은 약 21.51, ROE는 약 1.80입니다.
그럼 이제 각 종목이 속한 업계(Category)의 PER, ROE 평균값으로 대체해보겠습니다.lambda 함수를 이용해 각 업계별로 .mean()값을 구한 뒤 .fillna()로 평균값을 적용합니다.
fill_RoePer_df = fill_Dividend_df.groupby('Category').apply(lambda x: x.fillna(x.mean())) fill_RoePer_df
fill_RoePer_df[fill_RoePer_df['Name']=="삼일씨엔에스"]
삼일씨엔에스(004440)의 비어있던 PER, ROE가 건축자재종목 평균 PER, ROE로 대체되었습니다!
4) 기타 함수를 사용한다.
평균, 중앙값 등 자주 사용되는 내장함수 말고, 특정 분야에서만 사용하는 함수를 사용해 결측값을 대체해야할 수도 있습니다.
예를 들어, PER = 시가총액/순이익 = 주가/EPS이기 때문에, 이 식을 활용할 수만 있다면 평균값을 가져다 쓰는 것보다 더 정확한 값으로 대체할 수 있을 겁니다. (물론 여기서는 22년 5월 15일의 주가와 21년 4사분기의 EPS가 혼재되어있습니다...)
그래도 방식 자체는 간단합니다. 똑같이 .fillna()를 사용하면 됩니다. 그럼 식을 정의한 뒤 적용해보겠습니다.
def cal_per(close, eps): per = close/eps return per fill_df = fill_Dividend_df.copy() # fill_Dividend_df라고 하는 것이 맥락상 맞겠으나, 옆으로 길어지면 너무 보기 힘들 것 같아 df를 사용했습니다. fill_df['PER']= df['PER'].fillna(cal_per(df['Close'],df['EPS'])) fill_df.iloc[222:225]
ROE는 정의하지 않았기에 그대로 null값입니다. 이렇게 특정한 함수를 정의해서 활용할 수도 있고, 데이터프레임 내의 다른 칼럼값들도 사용할 수 있습니다.
반응형'Data & ML & AI > Pandas & Scikit-Learn' 카테고리의 다른 글
5. 판다스를 활용한 로그변환 (3) 2022.05.30 4. 판다스를 활용한 이상치 처리(boxplot, IQR) (0) 2022.05.29 2. 판다스를 활용한 Null값 제거 (결측행, 결측열 제거) (0) 2022.05.23 1. 판다스를 활용한 자료탐색 기초(+그래프그리기) (1) 2022.05.15 0. 들어가는 말 (1) 2022.05.14