-
[Pandas] pd.merge 속도 빠르게 바꾸기Data & ML & AI/Pandas & Scikit-Learn 2023. 3. 2. 12:16반응형
새로 서비스를 개발하는데 request에 대한 반응이 너무 느린 문제가 발생하였습니다.
모델 돌아가는게 느린가? 모델을 더 경량화 해야하나? 했는데
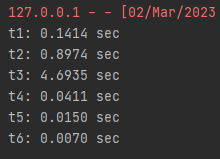
t3 : pd.merge 하는 부분... pd.merge 가 압도적으로 가장 많은 시간을 잡아먹고 있음을 확인할 수 있었습니다.
pd.merge에 소요되는 시간을 줄여봅시다.
아래의 글을 참조했습니다.
FAST PANDAS LEFT JOIN (357x faster than pd.merge)
Explore and run machine learning code with Kaggle Notebooks | Using data from Riiid Answer Correctness Prediction
www.kaggle.com
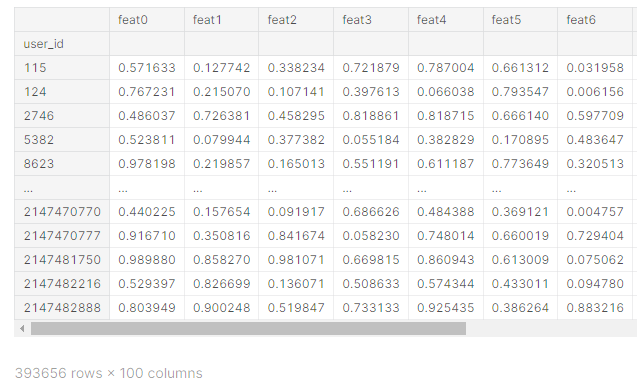
위의 글에서 사용된 데이터프레임은 위와 같이 생겼다고 합니다. 1) 매우 기본적인 형태의 pd.merge()
df_test.merge(df_user, how='left', on='user_id') # 1.67 s ± 74.7 ms per loop2) right_index=True
df_test.merge(df_user, how='left', left_on='user_id', right_index=True) # 128 ms ± 3.85 ms per loopright_index=True를 덧붙인것만으로도 약 13배가 빨라졌습니다!
3) right_index=True + 사전에 먼저 필터링하기
df_test.merge(df_user.loc[df_user.index.isin(df_test['user_id'])], how='left', left_on='user_id', right_index=True) # 35.2 ms ± 798 µs per loopdf_user를 그대로 가져다 붙여도 컴퓨터가 알아서 merge를 해주긴 하지만,
그 이전에 먼저 우리가 필터링을 해주면 훨씬 빨라집니다!
1)에 비해 약 45배가 빨라졌군요!
4) concat 이용하기
pd.concat([df_test.reset_index(drop=True), df_user.reindex(df_test['user_id'].values).reset_index(drop=True)], axis=1) # 5.03 ms ± 221 µs per loopconcat이 훨씬 빠르다고 하네요!
- df_test에서 index에 있던 'user_id' 를 칼럼으로 집어넣고,
- df_user의 index를 df_test의 user_id 순으로 재정렬해서
그냥 갖다 붙인겁니다!
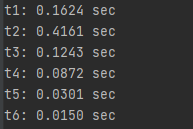
훨씬 빨라졌습니다
반응형'Data & ML & AI > Pandas & Scikit-Learn' 카테고리의 다른 글