-
8. 판다스를 활용한 원핫인코딩(One hot encoding)Data & ML & AI/Pandas & Scikit-Learn 2022. 6. 10. 01:14반응형
기본적으로 모델학습에 범주형 변수를 활용하기 위해서는 수치화 하는 과정이 필요합니다.
가장 쉬운 방법은 미국=1, ... 일본=81, 한국=82...와 같은 방식으로 코드를 부여하는 것입니다.하지만 당연하게도 이 수치를 그대로 활용하면 문제가 발생할 수 밖에 없습니다.
(미국 + 일본 = 한국)이 되어버리는건 너무나도 이상하죠.이를 가장 손쉽게 해결하는 방법은 원핫인코딩(one-hot-encoding)입니다.
통계적인 관점에서는 더미변수(dummy variable)를 생성하는 것입니다.sklearn의 데이터셋인 house_prices 데이터셋의 일부를 활용해 실습해보겠습니다.
import pandas as pd from sklearn.datasets import fetch_openml housing = fetch_openml(name="house_prices", as_frame=True) X = housing['data'] feature_names = housing['feature_names'] df = pd.DataFrame(X, columns = feature_names) df
여기서 데이터타입이 object인 칼럼 하나만 골라 사용하겠습니다.
df.groupby(['MSZoning']).size() # MSZoning # C (all) 10 # FV 65 # RH 16 # RL 1151 # RM 218 # dtype: int64MSZoning이 범주 개수도 너무 많지도 않고 실습하기에 딱인 느낌입니다.
원핫인코딩(One-hot-encoding)
판다스를 이용하면 손쉽게 원핫인코딩을 수행할 수 있습니다.
data = df['MSZoning'].iloc[45:55] print(data) # 45 RL # 46 RL # 47 FV # 48 RM # 49 RL # 50 RL # 51 RM # 52 RM # 53 RL # 54 RL # Name: MSZoning, dtype: object # pd.get_dummies(X) one_hot_df = pd.get_dummies(data) one_hot_df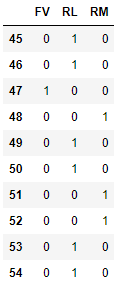
한번에 2개 이상의 칼럼에 대해 원핫인코딩을 진행하는 것도 가능합니다.
data = df[['MSZoning','LotShape']].iloc[45:55] one_hot_df = pd.get_dummies(data) one_hot_df
MSZoning 칼럼과 LostShape 칼럼의 범주형 데이터에 대해 원핫인코딩을 진행하였습니다. 반응형'Data & ML & AI > Pandas & Scikit-Learn' 카테고리의 다른 글
[Pandas] pd.merge 속도 빠르게 바꾸기 (2) 2023.03.02 9. Scikit Learn을 활용한 train-test 데이터셋 나누기 (cross validation, K-fold) (1) 2022.08.11 7. scikit-learn을 활용한 간단한 회귀모델(regression with LinearRegression) (1) 2022.06.08 6. scikit-learn을 활용한 간단한 분류모델 (classification with LogisticRegression) (0) 2022.06.03 5. 판다스를 활용한 로그변환 (3) 2022.05.30