-
6. scikit-learn을 활용한 간단한 분류모델 (classification with LogisticRegression)Data & ML & AI/Pandas & Scikit-Learn 2022. 6. 3. 01:11반응형
지난 글 까지는 제가 크롤링한 데이터를 사용했지만,
쉽게 내용을 정리하기 위해서는 역시 많은 사람들이 이미 정리해놓은 데이터를 사용하는 것이 더 편하고 직관적으로 좋기 때문에 지금부터는 sklean에 빌트인 된 데이터셋을 사용하려고 합니다.sklearn에 빌트인 된 대표적인 toy data 목록은 다음과 같습니다.
- load_boston: 보스톤 집값 데이터
- load_breast_cancer: 위스콘신 유방암 환자 데이터
- load_diabetes: 당뇨병 환자 데이터
- load_digits: 손글씨 데이터
- load_iris: 아이리스 붓꽃 데이터
- load_linnerud: multi-output regression 용 데이터
- load_wine: 와인 데이터
저는 이 중 와인데이터를 활용해 보겠습니다.
1. 데이터 가져오기
import pandas as pd from sklearn.datasets import load_wine wine = load_wine() # X X = wine['data'] feature_names = wine['feature_names'] # Y Y = wine['target'] df = pd.DataFrame(X, columns = feature_names) df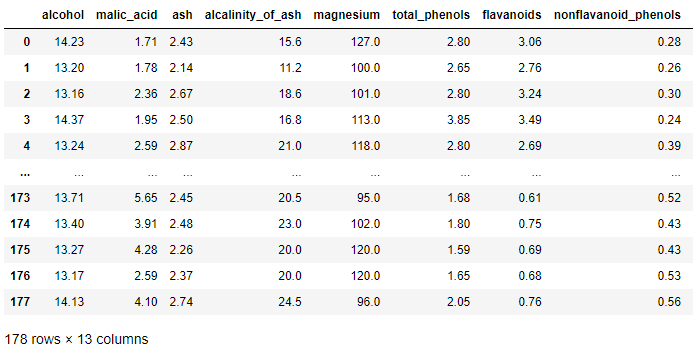
가져온 데이터를 좀 더 살펴보겠습니다.
print(wine['target_names']) print(Y) print(Y.shape) # ['class_0' 'class_1' 'class_2'] # [0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 # 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 # 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 # 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 # 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2] # (178,)target(Y)는 총 3개의 class로 이루어져 있습니다.
그래프를 이용해 좀 더 직관적으로 확인해봅시다.
import matplotlib.pyplot as plt fig, ax = plt.subplots() ax.scatter(df['alcohol'], df['malic_acid'], c=Y)
matplotlib으로 산점도를 그려봅시다 alcohol과 malic_acid 분포도 만으로도 와인종류(class)가 어느정도 구분되는 느낌입니다.
pd.plotting.scatter_matrix(df, c=Y, figsize=(10, 10),alpha=.8)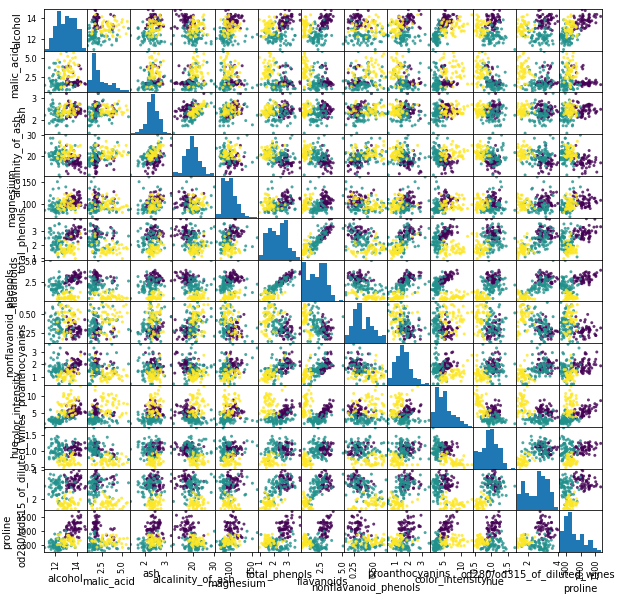
모든 칼럼에 대해 이변량 분포를 확인해 볼 수 있습니다. 2. train-test 데이터셋 나누기
모델학습에 사용할 train data, 모델성능 확인을 위한 test data로 나누어 줍니다.
sklearn의 train_test_split을 활용하면 손쉽게 처리할 수 있습니다.from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(X, Y, stratify=Y, random_state=777) print(X_train.shape, X_test.shape) print(y_train.shape, y_test.shape) # (133, 13) (45, 13) # (133,) (45,)- staratify : target 데이터(Y)의 분포 비율을 고려해서 적절히 train, test set 데이터를 만듭니다. 분류모델에서만 사용하는 것을 추천합니다.
- random_state : '777'이라는 고정된 랜덤시드를 사용합니다. 데이터셋을 나눌 때마다 데이터셋이 서로 다르게 만들어지는 것을 막습니다. 모델학습, 실험을 여러번 진행할 때, 데이터셋으로 인한 랜덤요소를 제거하고 각 모델 간 성능을 비교할 수 있습니다.
3. 정규화
물론 지금 이대로 그냥 모델을 학습시키기 시작해도 모델 학습이 진행되기는 합니다.
그치만 X의 각 칼럼별 평균값을 볼까요?
(물론 표준편차, 중앙값 등등 다른 기술통계치도 보는 것이 좋습니다. 하지만 여기선 생략합니다.)df.mean()alcohol 13.000618 malic_acid 2.336348 ash 2.366517 alcalinity_of_ash 19.494944 magnesium 99.741573 total_phenols 2.295112 flavanoids 2.029270 nonflavanoid_phenols 0.361854 proanthocyanins 1.590899 color_intensity 5.058090 hue 0.957449 od280/od315_of_diluted_wines 2.611685 proline 746.893258 dtype: float64nonflavanoid_phenols의 평균은 0.3인데 proline의 평균은 746입니다.
칼럼마다 scale이 매우 다르다는 것인데, 이 경우 Y를 분류하는데에 미치는 영향 정도가 달라지게 됩니다.
보다 원활한 학습의 진행을 위해서는 정규화를 진행할 필요가 있습니다.
분야에 따라 서로 각기다른 정규화를 사용하기도 하고, 새로운 방식을 만들어내기도 합니다.sklearn.preprocessing에서 제공하는 대표적인 정규화 scaler는 다음과 같습니다.
- StandardScaler : (평균=0, 분산=1)이 되도록 조정합니다.
- MinMaxScaler : 모든 값이 0~1 사이에 오도록(최대값=1, 최소값=0) 조정합니다.
- RobustScaler : 최대, 최솟값 대신 사분위값(Q1, Q2, Q3)를 사용해 조정합니다.
여기서는 MinMaxScaler를 사용하겠습니다.
from sklearn.preprocessing import MinMaxScaler scaler = MinMaxScaler() scaler.fit(X_train) X_scaled_train = scaler.transform(X_train) pd.DataFrame(X_scaled_train).describe()
X_train 데이터셋을 기준으로 scaler를 설정한 뒤, X_train 데이터를 정규화 한 데이터 X_scaled_train 데이터셋을 생성했습니다.
모든 칼럼에서 (max=1, min=0)이 되었습니다.X_scaled_test = scaler.transform(X_test) pd.DataFrame(X_scaled_test).describe()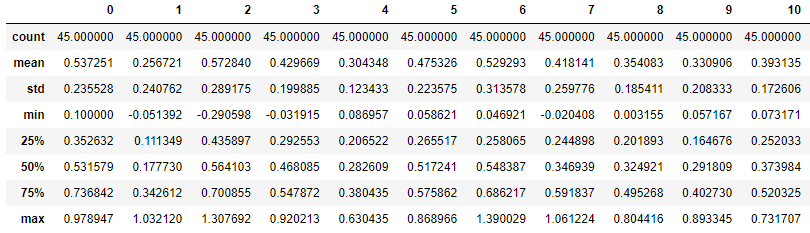
X_train 데이터셋을 기준으로 scaler를 설정한 것이기 때문에, X_scaled_test에서는 (max=1, min=0)가 아닐 수 있습니다.
4. 모델학습
분류기법 방법론으로 매우 다양한 방법론들이 있지만, 여기서는 로지스틱 회귀(logistr regression)을 활용하겠습니다.
from sklearn.linear_model import LogisticRegression model = LogisticRegression() model.fit(X_scaled_train, y_train) pred_train = model.predict(X_scaled_train) model.score(X_scaled_train, y_train) # 0.9849624060150376학습용 데이터에 대해 꽤나 높은 정확도의 모델이 만들어졌습니다.
pred_test = model.predict(X_scaled_test) model.score(X_scaled_test, y_test) # 1.0
1.0....????? ....???
아무리 toy data라지만 test가 만점받은건 또 처음봅니다. 너무 신기하네요.from sklearn.metrics import confusion_matrix print("훈련데이터셋 오차행렬 \n", confusion_matrix(y_train, pred_train), "\n") print("테스트데이터셋 오차행렬 \n", confusion_matrix(y_test, pred_test))훈련데이터셋 오차행렬 [[44 0 0] [ 1 51 1] [ 0 0 36]] 테스트데이터셋 오차행렬 [[15 0 0] [ 0 18 0] [ 0 0 12]]5. 성능결과 확인
분류모델의 성능평가지표로는 정확도 외에도 precision(정밀도), F1-score 등이 있습니다.
sklearn의 calssification_report를 사용하면 손쉽게 한번에 확인할 수 있습니다.from sklearn.metrics import classification_report print(classification_report(y_train, pred_train))precision recall f1-score support 0 0.98 1.00 0.99 44 1 1.00 0.96 0.98 53 2 0.97 1.00 0.99 36 accuracy 0.98 133 macro avg 0.98 0.99 0.99 133 weighted avg 0.99 0.98 0.98 133반응형'Data & ML & AI > Pandas & Scikit-Learn' 카테고리의 다른 글
8. 판다스를 활용한 원핫인코딩(One hot encoding) (0) 2022.06.10 7. scikit-learn을 활용한 간단한 회귀모델(regression with LinearRegression) (1) 2022.06.08 5. 판다스를 활용한 로그변환 (3) 2022.05.30 4. 판다스를 활용한 이상치 처리(boxplot, IQR) (0) 2022.05.29 3. 판다스를 활용한 Null값 대체(특정값, 평균, 특정함수) (0) 2022.05.24