-
7. scikit-learn을 활용한 간단한 회귀모델(regression with LinearRegression)Data & ML & AI/Pandas & Scikit-Learn 2022. 6. 8. 01:01반응형
지난 글에서는 분류문제를 다루었으므로 이번엔 간단한 회귀문제를 다루어보겠습니다.
이번에도 역시 scikit learn에 내장된 데이터셋 중 하나인 보스턴 주택가격 데이터셋을 사용해... 보고자 하였으나
DEPRECATED: load_boston is deprecated in 1.0 and will be removed in 1.2. The Boston housing prices dataset has an ethical problem. You can refer to the documentation of this function for further details.
윤리적인 이슈로 인해 언젠가 사라질 예정이라고 합니다. (참고)
따라서 그 대안으로 California housing dataset을 사용하겠습니다.
1. 데이터 가져오기
import pandas as pd from sklearn.datasets import fetch_openml housing = fetch_openml(name="house_prices", as_frame=True) # X X = housing['data'] feature_names = housing['feature_names'] # Y Y = housing['target'] df = pd.DataFrame(X, columns = feature_names) df
데이터 타입이 혼재되어 있습니다. 오늘은 간단히 회귀모델을 접해보기만 하려고 하니, 우선 수치형 데이터만 활용하겠습니다.
그리고 Id는 말 그대로 각 주택의 ID일 뿐이니 제거하고,
결측값이 있는 열은 그냥 제거하도록 하겠습니다.df0 = df.select_dtypes(include=['float','int']) df1 = df0.drop(['Id'], axis=1) df2 = df1.dropna(axis=1) df2
매우 단순한 모델을 돌려보고 싶을 뿐인데 여전히 칼럼이 33개로 너무 많네요.(사실 많은게 아니지만)
히스토그램을 그려본 뒤, 분포가 너무 쏠려있는 칼럼은 그냥 제거하도록 하겠습니다.(물론 실제 분석이라면 당연히 이러시면 안됩니다.)
df2.hist(bins=20, figsize=(10,10))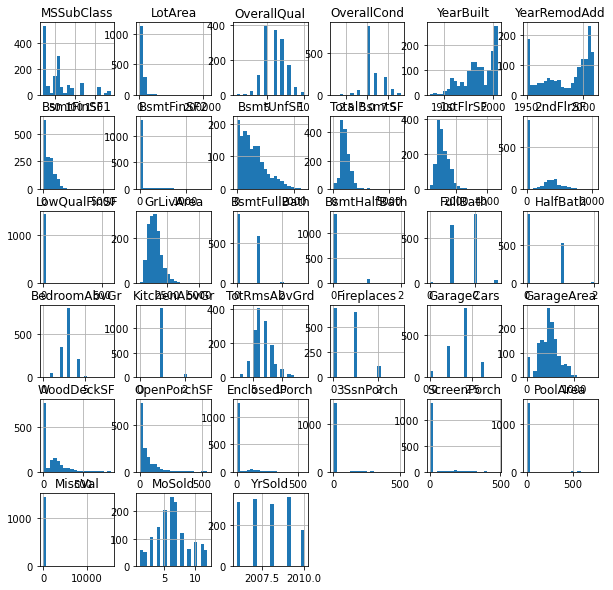
toy dataset치고는 칼럼이 많네요 drop_col = ['LotArea','BsmtFinSF2','LowQualFinSF','2ndFlrSF','BsmtHalfBath','KitchenAbvGr','WoodDeckSF','OpenPorchSF','EnclosedPorch','3SsnPorch','ScreenPorch','PoolArea','MiscVal'] df3 = df2.drop(drop_col, axis=1) df3.hist(bins=30, figsize=(8,6))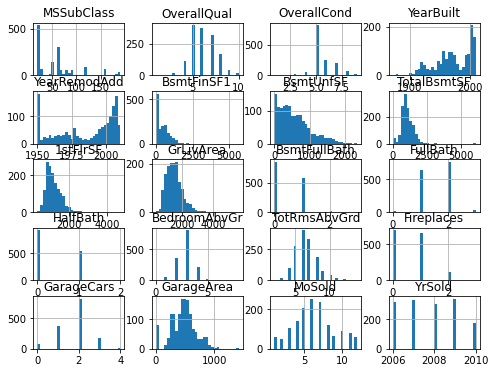
적당히 손을 봐주었습니다. 적당히 20개의 칼럼만 챙겨 가보도록 하겠습니다.
2. train-test 데이터셋 나누기
모델학습에 사용할 train data, 모델성능 확인을 위한 test data로 나누어 줍니다.
sklearn의 train_test_split을 활용하면 손쉽게 처리할 수 있습니다.from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(df3, Y, random_state=777) print(X_train.shape, X_test.shape) print(y_train.shape, y_test.shape) # (1095, 20) (365, 20) # (1095,) (365,)- random_state : '777'이라는 고정된 랜덤시드를 사용합니다. 데이터셋을 나눌 때마다 데이터셋이 서로 다르게 만들어지는 것을 막습니다. 모델학습, 실험을 여러번 진행할 때, 데이터셋으로 인한 랜덤요소를 제거하고 각 모델 간 성능을 비교할 수 있습니다.
- 분류모델 때와는 다르게 staratify가 없습니다.
print(y_train.mean(),'\t',y_train.std()) print(y_test.mean(),'\t',y_test.std()) # 182924.0575342466 82515.3962851781 # 174912.61095890412 69169.4094071819대충 너무 편중되지 않게 랜덤하게 잘 나뉘어진 느낌입니다.
3. 정규화
물론 지금 이대로 그냥 모델을 학습시키기 시작해도 모델 학습이 진행되기는 합니다.
그치만 X의 각 칼럼별 평균값을 볼까요?
(물론 표준편차, 중앙값 등등 다른 기술통계치도 보는 것이 좋습니다. 하지만 여기선 생략합니다.)df3.mean()MSSubClass 56.897260 OverallQual 6.099315 OverallCond 5.575342 YearBuilt 1971.267808 YearRemodAdd 1984.865753 BsmtFinSF1 443.639726 BsmtUnfSF 567.240411 TotalBsmtSF 1057.429452 1stFlrSF 1162.626712 GrLivArea 1515.463699 BsmtFullBath 0.425342 FullBath 1.565068 HalfBath 0.382877 BedroomAbvGr 2.866438 TotRmsAbvGrd 6.517808 Fireplaces 0.613014 GarageCars 1.767123 GarageArea 472.980137 MoSold 6.321918 YrSold 2007.815753 dtype: float64Fireplaces의 평균은 0.6인데 YrSold의 평균은 2007입니다. 하나는 면적이고 하나는 년도이니 단위(scale)가 다른건 당연합니다.
문제는 scale이 매우 다를 경우, Y를 예측하는데 미치는 영향 정도가 달라지게 된다는 점입니다.
보다 원활한 학습의 진행을 위해서는 정규화를 진행할 필요가 있습니다.
분야에 따라 서로 각기다른 정규화를 사용하기도 하고, 새로운 방식을 만들어내기도 합니다.sklearn.preprocessing에서 제공하는 대표적인 정규화 scaler는 다음과 같습니다.
- StandardScaler : (평균=0, 분산=1)이 되도록 조정합니다.
- MinMaxScaler : 모든 값이 0~1 사이에 오도록(최대값=1, 최소값=0) 조정합니다.
- RobustScaler : 최대, 최솟값 대신 사분위값(Q1, Q2, Q3)를 사용해 조정합니다.
여기서는 MinMaxScaler를 사용하겠습니다.
from sklearn.preprocessing import MinMaxScaler scaler = MinMaxScaler() scaler.fit(X_train) X_scaled_train = scaler.transform(X_train) pd.DataFrame(X_scaled_train).describe()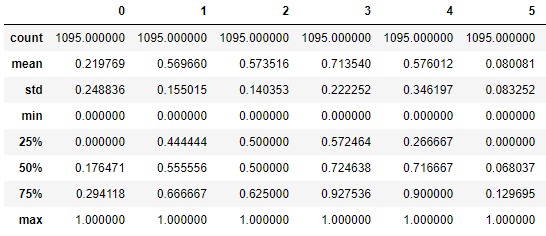
X_train 데이터셋을 기준으로 scaler를 설정한 뒤, X_train 데이터를 정규화 한 데이터 X_scaled_train 데이터셋을 생성했습니다.
모든 칼럼에서 (max=1, min=0)이 되었습니다.X_scaled_test = scaler.transform(X_test) pd.DataFrame(X_scaled_test).describe()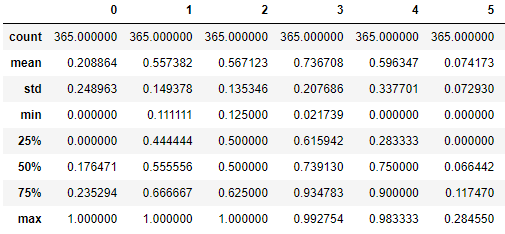
X_train 데이터셋을 기준으로 scaler를 설정한 것이기 때문에, X_scaled_test에서는 (max=1, min=0)가 아닐 수 있습니다.
4. 모델학습
회귀관련 방법론으로 매우 다양한 방법론들이 있지만, 여기서는 선형회귀(linear regression)을 활용하겠습니다.
from sklearn.linear_model import LinearRegression model = LinearRegression() model.fit(X_scaled_train, y_train) pred_train = model.predict(X_scaled_train) model.score(X_scaled_train, y_train) # 0.78425963176437110.78의 설명력(R square)를 가지고 있습니다.
대충대충 만든 모델임에도 기대보다 높은 정확도의 모델이 만들어졌습니다.pred_test = model.predict(X_scaled_test) model.score(X_scaled_test, y_test) # 0.8739612215908217테스트 데이터에 대해서는 0.87이라는 매우 높은 설명력을 가지고 있습니다.
5. 성능결과 확인
회귀모델에서 가장 많이 사용되는 평가지표 중 하나는 RMSE(Root Mean Squared Error)입니다.
import numpy as np from sklearn.metrics import mean_squared_error MSE = mean_squared_error(y_test,pred_test) np.sqrt(MSE) # 24522.820529629218평균적으로 24,522$ 내외의 오차가 발생한 것으로 나타나고 있습니다.
y_test.mean() # 174912.61095890412주택 가격이 평균 약 175,000 달러인데, 평균적인 오차가 대략 24,500 달러라고 하면 오차가 꽤 큰 것으로 느껴집니다.
반응형'Data & ML & AI > Pandas & Scikit-Learn' 카테고리의 다른 글
9. Scikit Learn을 활용한 train-test 데이터셋 나누기 (cross validation, K-fold) (1) 2022.08.11 8. 판다스를 활용한 원핫인코딩(One hot encoding) (0) 2022.06.10 6. scikit-learn을 활용한 간단한 분류모델 (classification with LogisticRegression) (0) 2022.06.03 5. 판다스를 활용한 로그변환 (3) 2022.05.30 4. 판다스를 활용한 이상치 처리(boxplot, IQR) (0) 2022.05.29